This Machine Learning Paper Introduces JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
The evaluation of jailbreaking attacks on LLMs presents challenges like lacking standard evaluation practices, incomparable cost and success rate calculations, and numerous works that are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. Despite LLMs aiming to align with human values, such attacks can still prompt harmful or unethical content, suggesting that even advanced LLMs aren’t fully adversarially aligned.
Prior research demonstrates that even top-performing LLMs lack adversarial alignment, making them susceptible to jailbreaking attacks. These attacks can be initiated through various means, such as hand-crafted prompts, auxiliary LLMs, or iterative optimization. While defense strategies have been proposed, LLMs remain highly vulnerable. Consequently, benchmarking the advancement of jailbreaking attacks and defenses is crucial, particularly for safety-critical applications.
Researchers from the University of Pennsylvania, ETH Zurich, EPFL, and Sony AI introduce JailbreakBench, a benchmark designed to standardize best practices in the evolving field of LLM jailbreaking. Its core principles focus on complete reproducibility through open-sourcing jailbreak prompts, extensibility to accommodate new attacks, defenses, and LLMs, and accessibility of the evaluation pipeline for future research. It includes a leaderboard to track the state-of-the-art jailbreaking attacks and defenses, aiming to facilitate comparison among algorithms and models. Early results highlight Llama Guard as a preferred jailbreaking evaluator, indicating the susceptibility of both open- and closed-source LLMs to attacks despite some mitigation by existing defenses.
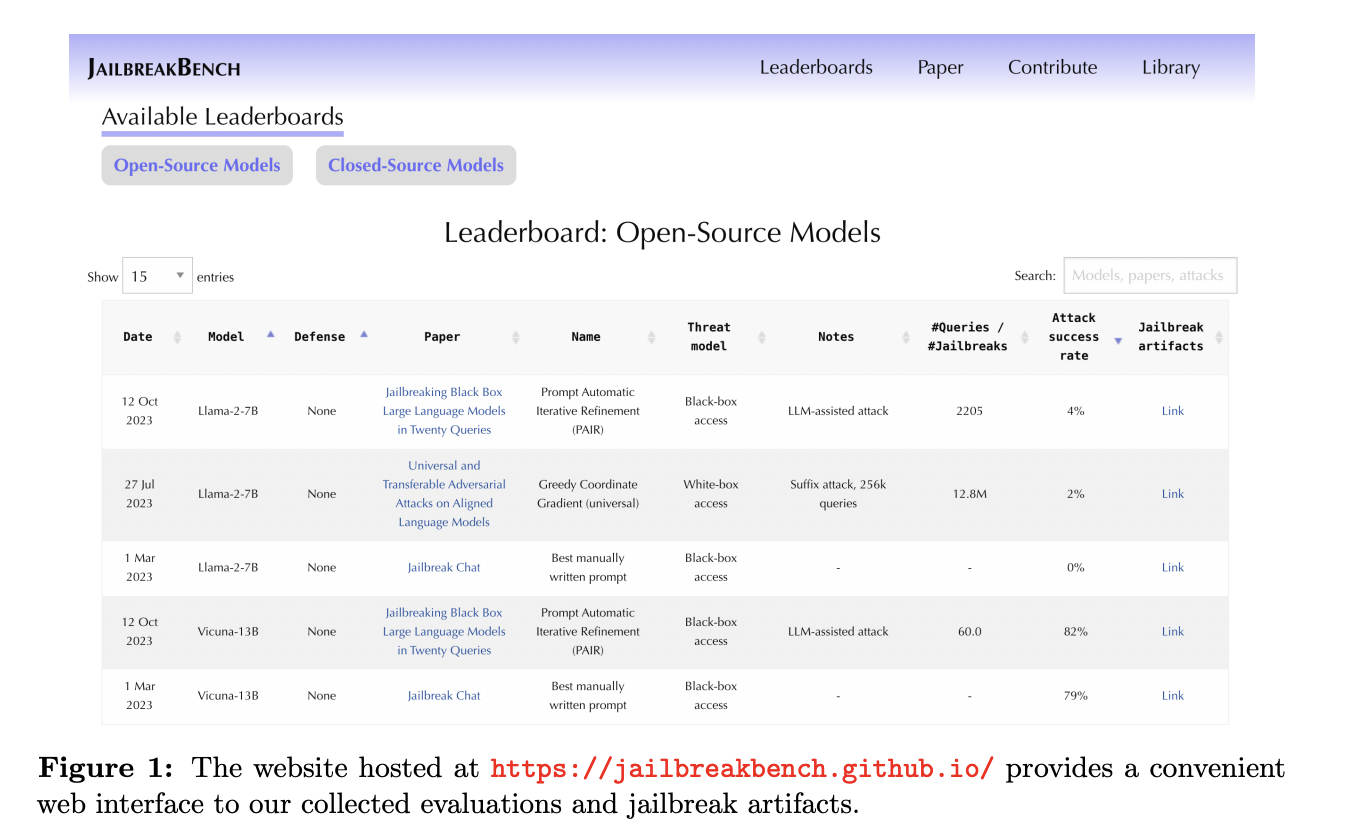
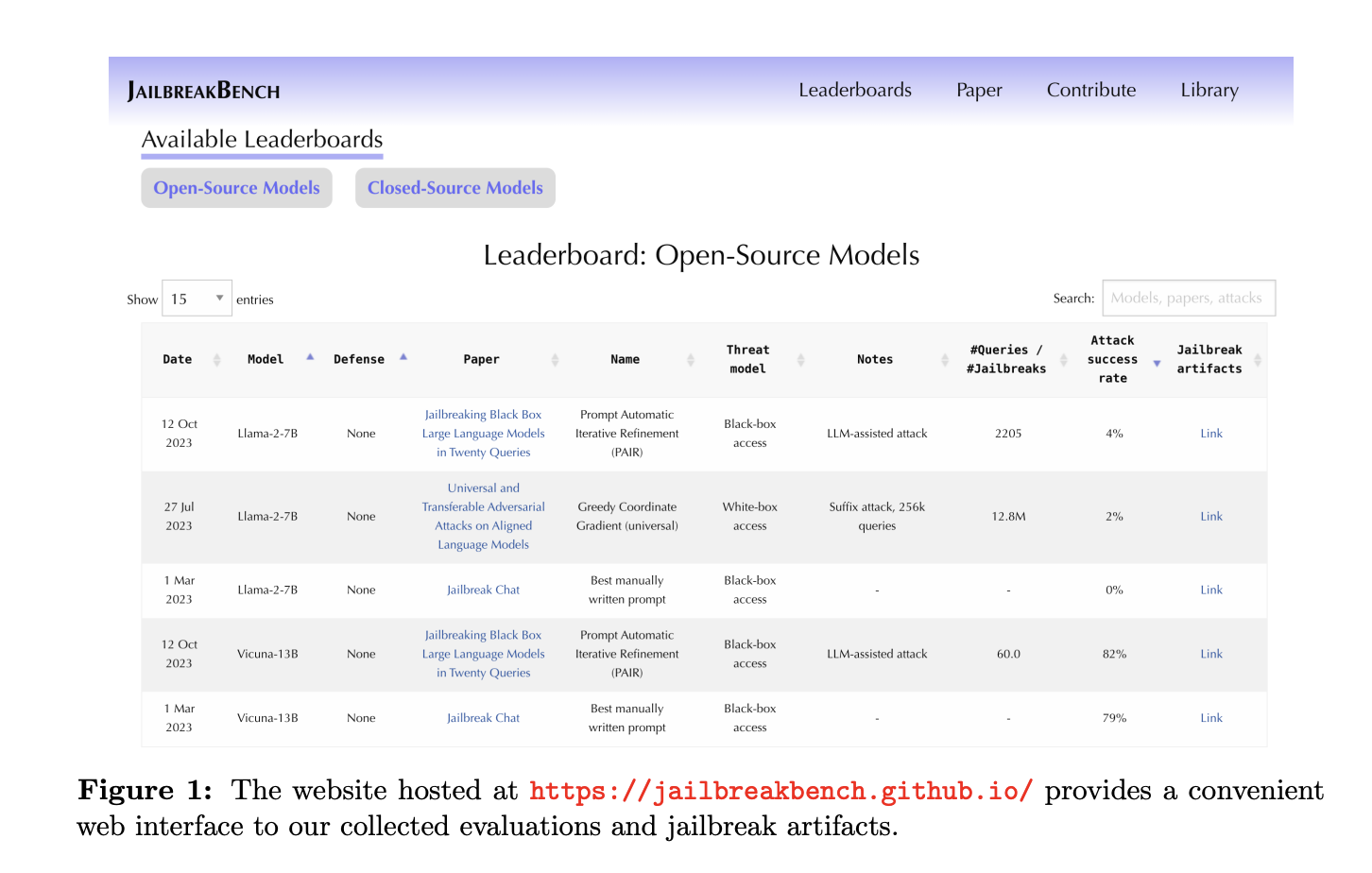
JailbreakBench ensures maximal reproducibility by collecting and archiving jailbreak artifacts, aiming to establish a stable basis of comparison. Their leaderboard tracks the state-of-the-art jailbreaking attacks and defenses, aiming to identify leading algorithms and establish open-sourced baselines. They accept various types of jailbreaking attacks and defenses, all evaluated using the same metrics. Their red-teaming pipeline is efficient, affordable, and cloud-based, eliminating the requirement for local GPUs.
Comparing three jailbreaking attack artifacts within JailbreakBench, Llama-2 demonstrates greater robustness than Vicuna and GPT models, likely because of explicit fine-tuning on jailbreaking prompts. The AIM template from JBC effectively targets Vicuna but fails on Llama-2 and GPT models, potentially due to patching by OpenAI. GCG exhibits lower jailbreak percentages, possibly attributed to more challenging behaviors and a conservative jailbreak classifier. Defending models with SmoothLLM and perplexity filter significantly reduces ASR for GCG prompts, while PAIR and JBC remain competitive, likely due to semantically interpretable prompts.
To conclude, This research introduced an innovative method, JailbreakBench, an open-sourced benchmark for Evaluating Jailbreak attacks, comprising of (1) JBB-Behaviors dataset featuring 100 unique behaviors, (2) evolving repository of adversarial prompts termed jailbreak artifacts, (3) standardized evaluation framework with defined threat model, system prompts, chat templates, and scoring functions, and (4) a leaderboard monitoring attack and defense performance across LLMs.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.





