Researchers from KAUST and Harvard Introduce MiniGPT4-Video: A Multimodal Large Language Model (LLM) Designed Specifically for Video Understanding
In the rapidly evolving digital communication landscape, integrating visual and textual data for enhanced video understanding has emerged as a critical area of research. Large Language Models (LLMs) have demonstrated unparalleled capabilities in processing and generating text, transforming how to interact with digital content. However, these models have primarily been text-centric, leaving a significant gap in their ability to comprehend and interact with the more complex and dynamic medium of video.
Unlike static images, videos offer a rich tapestry of temporal visual data coupled with textual information, such as subtitles or conversations. This combination presents a unique challenge: designing models to process this multimodal data and understand the nuanced interplay between visual scenes and accompanying text. Traditional methods have made strides in this direction, yet they often fall short of capturing the full depth of videos, leading to a loss of critical information. Approaches like spatial pooling and simplistic tokenization have been unable to fully leverage the temporal dynamics intrinsic to video data fully, underscoring the need for more advanced solutions.
KAUST and Harvard University researchers present MiniGPT4-Video, a pioneering multimodal LLM tailored specifically for video understanding. Expanding on the success of MiniGPT-v2, which revolutionized the translation of visual features into actionable insights for static images, MiniGPT4-Video takes this innovation to the realm of video. By processing visual and textual data sequences, the model achieves a deeper comprehension of videos, surpassing existing state-of-the-art methods in interpreting complex multimodal content.
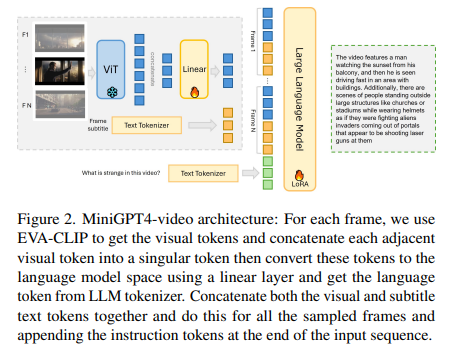
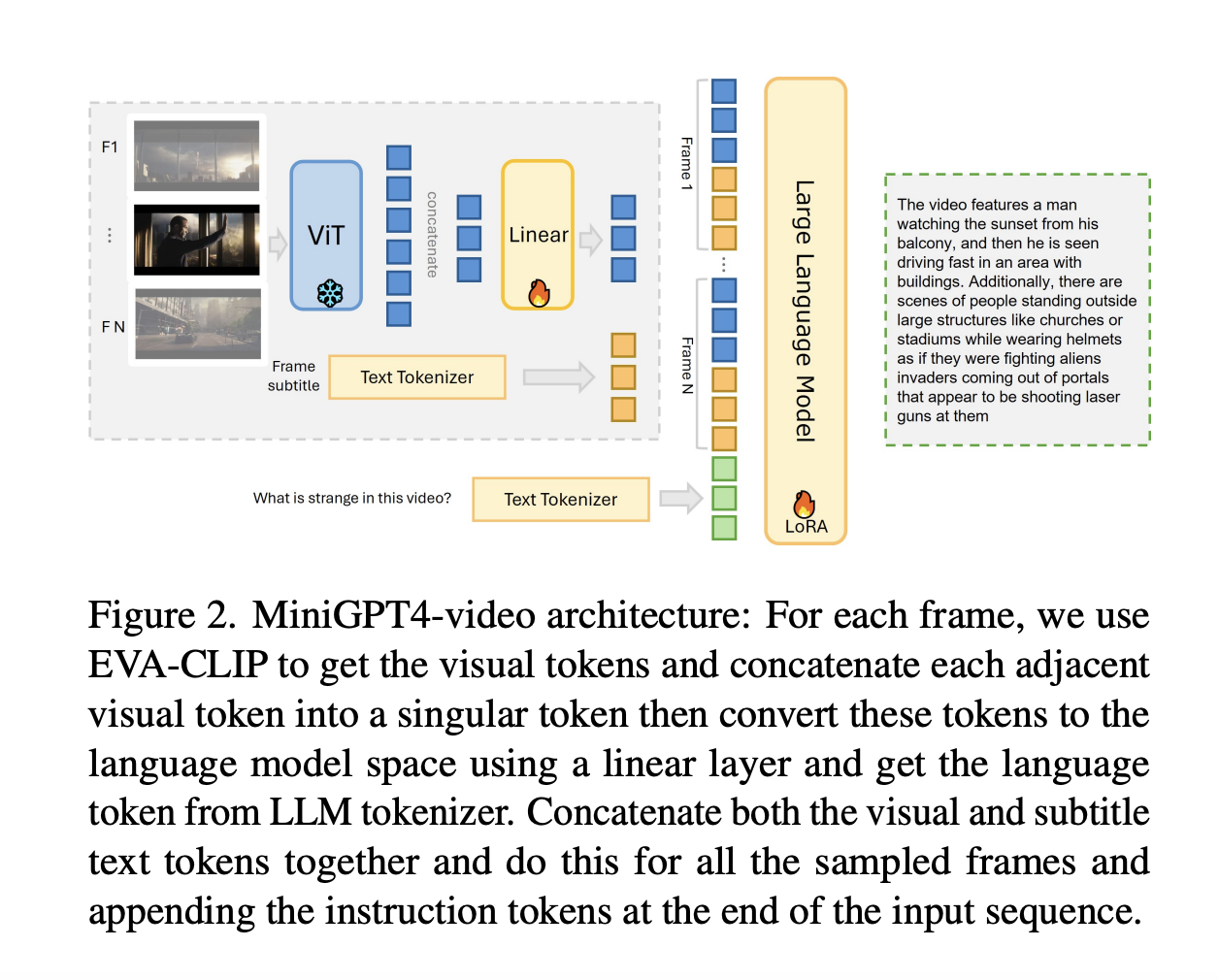
MiniGPT4-Video distinguishes itself through its innovative approach to handling multimodal inputs. The model reduces information loss by concatenating every four adjacent visual tokens, effectively lowering the token count while preserving essential visual details. It then enriches this visual representation with textual data, incorporating subtitles for each frame. This method allows MiniGPT4-Video to process visual and textual elements concurrently, providing a comprehensive understanding of video content. The model’s performance is noteworthy, demonstrating significant improvements across several benchmarks, including MSVD, MSRVTT, TGIF, and TVQA. Specifically, it registered gains of 4.22%, 1.13%, 20.82%, and 13.1% on these benchmarks, respectively.
One of the most compelling aspects of MiniGPT4-Video is its utilization of subtitles as input. This inclusion has proven beneficial in contexts where textual information complements visual data. For example, in the TVQA benchmark, the integration of subtitles led to a remarkable increase in accuracy, from 33.9% to 54.21%, underscoring the value of combining visual and textual data for enhanced video understanding. However, it’s also worth noting that for datasets primarily focused on visual questions, the addition of subtitles did not significantly impact performance, indicating the model’s versatility and adaptability to different types of video content.

In conclusion, MiniGPT4-Video offers a robust solution that adeptly navigates the complexities of integrating visual and textual data. By directly inputting both types of data, the model achieves a higher level of comprehension and sets a new benchmark for future research in multimodal content analysis. Its impressive performance across diverse benchmarks demonstrates its potential to revolutionize how to interact with, interpret, and leverage video content in various applications. As the digital landscape continues to evolve, models like MiniGPT4-Video pave the way for more nuanced and comprehensive approaches to understanding video’s rich, multimodal world.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





