Researchers at Intel Labs Introduce LLaVA-Gemma: A Compact Vision-Language Model Leveraging the Gemma Large Language Model in Two Variants (Gemma-2B and Gemma-7B)

Recent advancements in large language models (LLMs) and Multimodal Foundation Models (MMFMs) have spurred interest in large multimodal models (LMMs). Models like GPT-4, LLaVA, and their derivatives have shown remarkable performance in vision-language tasks such as Visual Question Answering and image captioning. However, their high computational demands have prompted exploration into smaller-scale LMMs.
Researchers from Cognitive AI, Intel Labs, introduce LLaVA-Gemma, a suite of vision-language assistants trained from Gemma LLM variants, Gemma-2B and Gemma-7B and inspired by progress in small yet capable visual language models (VLMs) like LLaVA-Phi. LLaVA-Gemma allows researchers to investigate the trade-offs between computational efficiency and the richness of visual and linguistic understanding by possessing two variants with different parameter sizes. Also, the researchers examine how a massively increased token set affects multi-modal performance.
LLaVA-Gemma follows the LLaVA framework with modifications, combining a pretrained vision encoder (like CLIP) and a pretrained language model (such as Gemma) via an MLP connector. It undergoes a two-stage training process: pretraining the MLP connector on a custom dataset, then jointly finetuning the language model and connector on multimodal instruction tuning examples. Deviations include using Gemma models for language backbone, employing the larger DINOv2 image encoder for vision, and exploring skipping the initial pretraining stage for improved performance. Both pretraining and finetuning stages are conducted with and without initial pretraining.
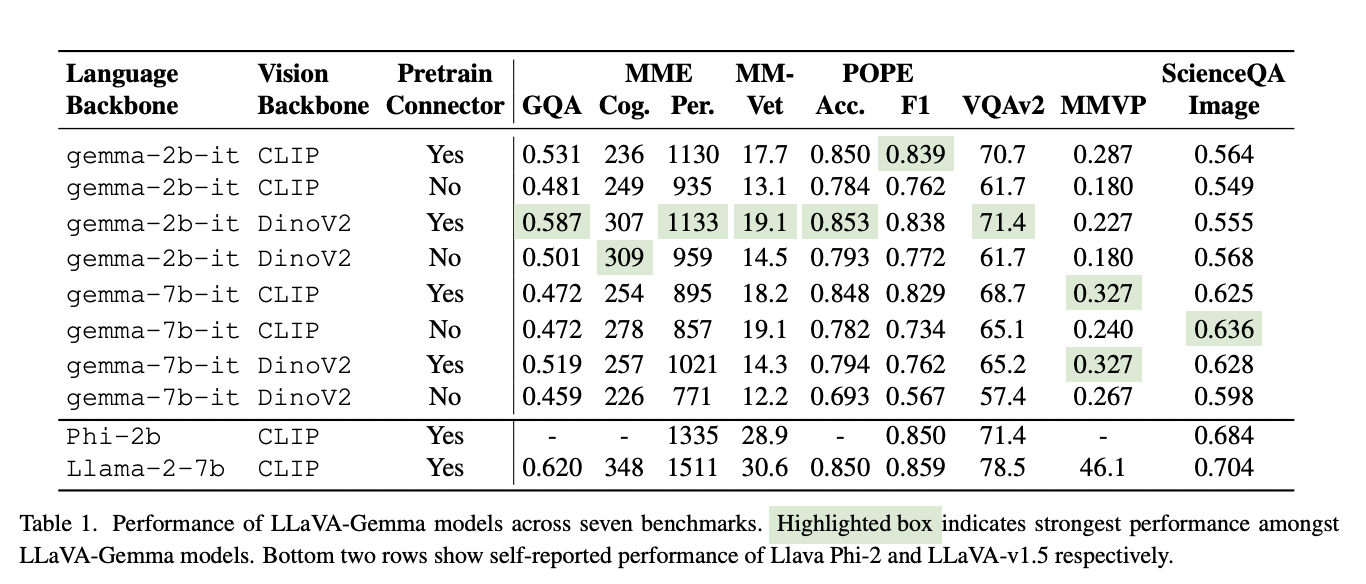
For the 2B backbone, DinoV2 variants outperform CLIP variants on all benchmarks except POPE-F1 and MMVP. Comparing the training and eval speed for the two model sizes, The training time for the Gemma-2B model on 8 Intel Gaudi 2® AI accelerators was 4 hours, while the larger Gemma-7B model required 16 hours to train under the same conditions. This indicates that the Gemma-7B model, with its increased parameter count, takes approximately four times longer to train than the Gemma-2B model. The relative speed of the Gemma7B model is thus 0.25x compared to the Gemma-2B model. These results highlight the trade-off between model size and training efficiency, with larger models requiring significantly more computational resources and time.
Contributions to this research are as follows:
1. Researchers introduce LLaVA-Gemma, an MMFM leveraging compact, powerful Gemma language models for efficient multimodal interactions.
2. They extensively evaluate Gemma-2B and Gemma-7B model variants, providing valuable insights into the tradeoffs between computational efficiency and the richness of visual and linguistic understanding in LLMs.
3. They present a deep exploration into alternate design choices and visualize attention with relevancy maps to enhance their understanding of the model’s performance and attention.
In conclusion, The research introduces LLaVA-Gemma, a compact vision-language model utilizing Gemma LLM in two variants, Gemma-2B and Gemma-7B. This research provides a unique opportunity for researchers to explore the trade-offs between computational efficiency and multimodal understanding in small-scale models. Evaluations demonstrate the versatility and effectiveness of LLaVA-Gemma across a range of datasets, highlighting its potential as a benchmark for future research in small-scale vision-language models.
Check out the Paper and HF Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.





