Tech Deep Dive: Building knowledge graphs
After a little break we are back with the Tech Deep Dive series! In this article, we will explain what knowledge graphs are, discuss their pros and cons, and delve into how Iris.ai uses them. If you’re interested in this series and want to be notified about the new articles, subscribe to our newsletter!
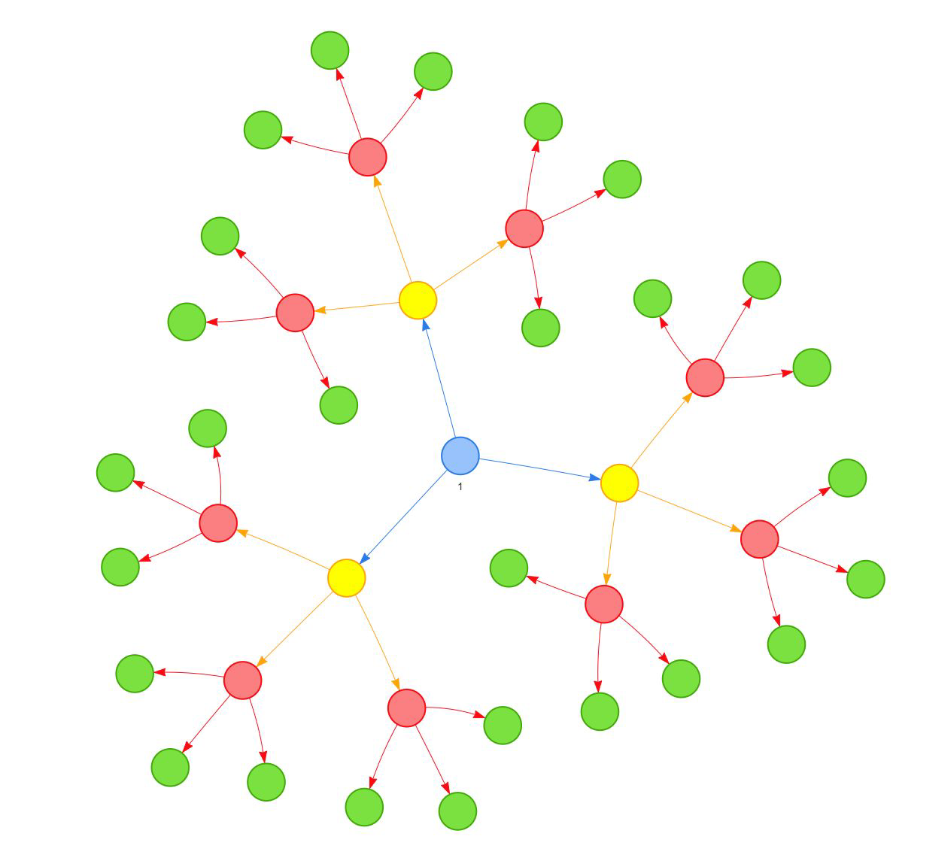
What is a knowledge graph?
A graph is a structure used to form a representation of any data. It is a big umbrella term, under which we can find knowledge graphs. A knowledge graph is a structured representation of information that captures relationships between entities in a way that is easily accessible and understandable for both humans and machines. It consists of nodes representing entities, connected by edges representing relationships or attributes.
Pros and cons of building knowledge graphs
Knowledge graphs are incredibly helpful in making sense of complex information. One of the advantages of using knowledge graphs is being able to easily see the relationship between the concepts based on the distance from one to the other and their connections. The way to think about it is to imagine a family tree – the family members are nodes in the graph and branches represent graph edges. When you look at the tree you can quickly tell what connection you have to your cousin and how connected the cousin is to, let’s say, your uncle. From that graphical representation you can see the connections faster and easier than if you would have to read a text about it. In using other representations of data like an embedding space for language, you can see if two concepts are similar to each other – each of them represented by one word. But the knowledge graph contains more information on, for example, types of concepts as well, and it can have attached a description to the concept, so you can easily get a better understanding. Overall, it’s more efficient for the people looking at the graph to quickly understand the relationship between any two objects.
Knowledge graphs try to condense a lot of information into graphical representation and therefore, they need a lot of computational power to operate. Operations with graphical data are usually very expensive and difficult to scale. Besides that knowledge graphs are useful representations for both humans and machines and are easy to validate by humans.
Factuality check using knowledge graphs
In the rapidly evolving field of natural language processing (NLP) and Language Models, abstractive summarization has emerged as a powerful technique for condensing vast amounts of information into concise summaries. However, as NLP models generate these summaries, ensuring their factuality and accuracy becomes a critical challenge. To address this issue, knowledge graphs have gained prominence as a valuable tool.
You can read about how the Iris.ai summarization model works and the issues with hallucination in “Tech Deep Dive: Extractive vs. abstractive summaries and how machines write them”.
In the abstractive summaries created by the machine it is difficult to properly assess the factuality, because the generated text can be read very fluently and still contain hallucinations. It’s very difficult to understand if the text is correct in terms of the factuality just by reading it.
At Iris.ai we are building a knowledge graph from the provided text. We are able to compare the knowledge graph based on the original scientific article and the knowledge graph based on the abstractive summarization generated by AI to see if there’s any factual discrepancy. We are basically training a model that is used to build a knowledge graph from any given text.
In the future we are planning to use the generated knowledge graph alongside the summarization model to bias the output token generation with the information from the knowledge graph. In short, the model will be using the objects and relationships from the knowledge graph to guide the model towards the factual information instead of using only the probability of the next word generation without any restrictions as in current models.
Other use cases
Another way we are already using knowledge graphs is in our Extraction model. In the “Tech Deep Dive: Extraction of table data (and why it’s difficult)” and the following Tech Deep Dive articles we have explained how the Extraction process looks like. As a part of the process, the clients provide us with what we call an ODL (Output Data Layout) – a spreadsheet with data points to be extracted. The graph is made with the entities given to us in the ODL. We search for entities with similar names to them with the embeddings model and connect these entities by their similarity to form a unified representation. That way we are broadening the ODL concepts and including contextual synonyms to make sure we won’t miss any important information for extraction.
Last year we also published a paper about “Leveraging knowledge graphs to update scientific word embeddings using latent semantic imputation”, where we inject knowledge that exists in the knowledge graph but is missing in the embeddings space. This helps bridge the gap between an embedding space and its representation of existing knowledge on the knowledge graph. We also compare this injection to other models using latent semantic imputation technique.
Key Takeaways
👉 Knowledge graph uses nodes and edges to represent the information.
👉 It is faster and more efficient to see the relationship between two data points in the knowledge graph that to read a text about it.
👉 Operations with graphical data are usually very expensive and difficult to scale.
👉 Iris.ai is building a knowledge graph from provided text and comparing it with the original scientific article to identify factual discrepancies. Future plans include using the knowledge graph alongside the summarization model to guide output token generation based on factual information.
Discover more from reviewer4you.com
Subscribe to get the latest posts to your email.





