Simplifying AI: A Dive into Lightweight Fine-Tuning Techniques | by Anurag Lahon
In natural language processing (NLP), fine-tuning large pre-trained language models like BERT has become the standard for achieving state-of-the-art performance on downstream tasks. However, fine-tuning the entire model can be computationally expensive. The extensive resource requirements pose significant challenges.
In this project, I explore using a parameter-efficient fine-tuning (PEFT) technique called LoRA to fine-tune BERT for a text classification task.

I opted for LoRA PEFT technique.
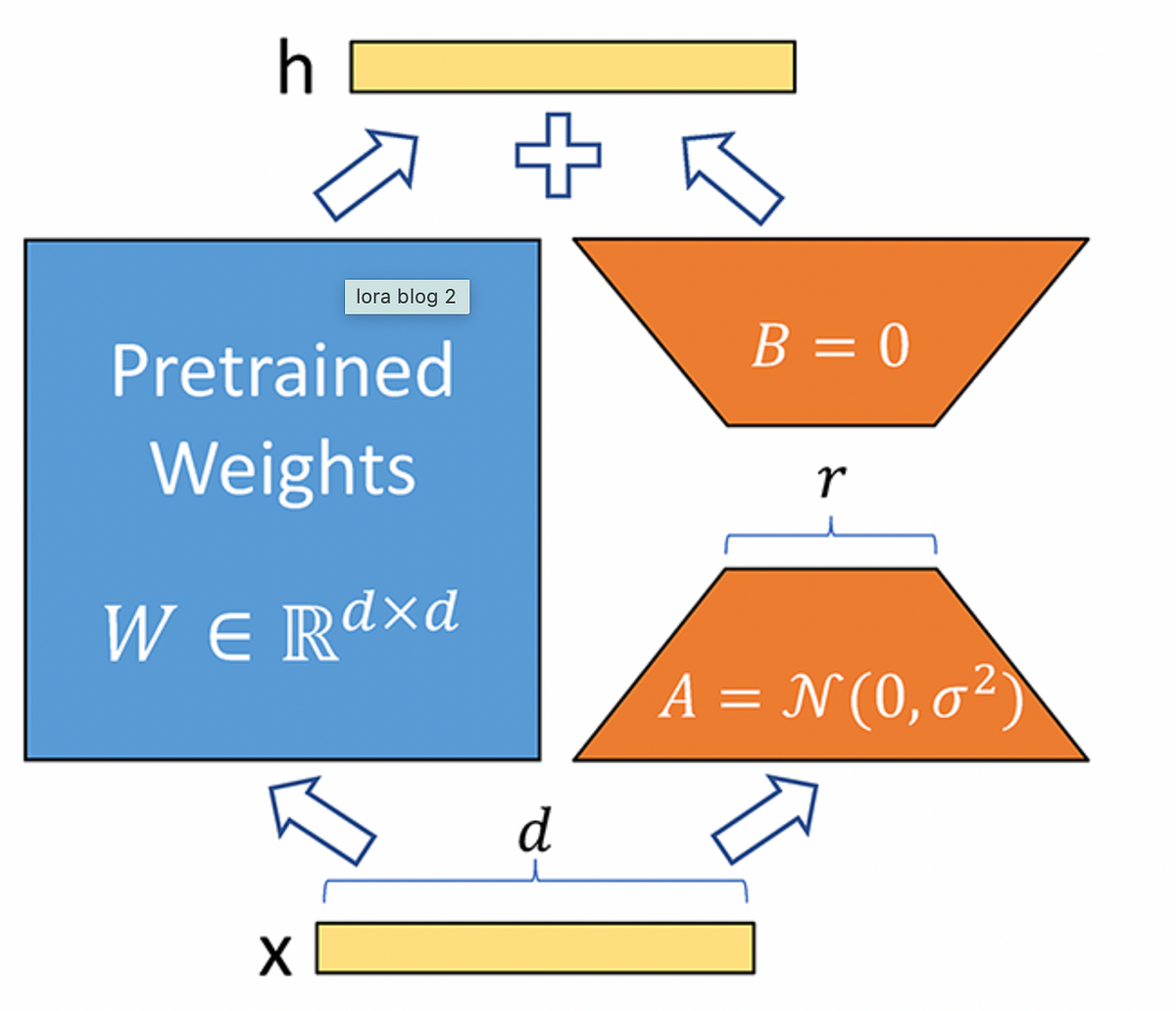
LoRA (Low-Rank Adaptation) is a technique for efficiently fine-tuning large pre-trained models by inserting small, trainable matrices into their architecture. These low-rank matrices modify the model’s behavior while preserving the original weights, offering significant adaptations with minimal computational resources.

In the LoRA technique, for a fully connected layer with ‘m’ input units and ’n’ output units, the weight matrix is of size ‘m x n’. Normally, the output ‘Y’ of this layer is computed as Y = W X, where ‘W’ is the weight matrix, and ‘X’ is the input. However, in LoRA fine-tuning, the matrix ‘W’ remains unchanged, and two additional matrices, ‘A’ and ‘B’, are introduced to modify the layer’s output without altering ‘W’ directly.
The base model I picked for fine-tuning was BERT-base-cased, a ubiquitous NLP model from Google pre-trained using masked language modeling on a large text corpus. For the dataset, I used the popular IMDB movie reviews text classification benchmark containing 25,000 highly polar movie reviews labeled as positive or negative.


I evaluated the bert-base-cased model on a subset of our dataset to establish a baseline performance.
First, I loaded the model and data using HuggingFace transformers. After tokenizing the text data, I split it into train and validation sets and evaluated the out-of-the-box performance:
The heart of the project lies in the application of parameter-efficient techniques. Unlike traditional methods that adjust all model parameters, lightweight fine-tuning focuses on a subset, reducing the computational burden.


I configured LoRA for sequence classification by defining the hyperparameters r and α. R controls the percentage of weights that are masked, and α controls the scaling applied to the masked weights to keep their magnitude in line with the original value. I masked 80% by setting r=0.2 and used the default α=1.
After applying LoRA masking, I retrained just the small percentage of unfrozen parameters on the sentiment classification task for 30 epochs.

LoRA was able to rapidly fit the training data and achieve 85.3% validation accuracy — an absolute improvement over the original model!
The impact of lightweight fine-tuning is evident in our results. By comparing the model’s performance before and after applying these techniques, we observed a remarkable balance between efficiency and effectiveness.


Fine-tuning all parameters would have required orders of magnitude more computation. In this project, I demonstrated LoRA’s ability to efficiently tailor pre-trained language models like BERT to custom text classification datasets. By only updating 20% of weights, LoRA sped up training by 2–3x and improved accuracy over the original BERT Base weights. As model scale continues growing exponentially, parameter-efficient fine-tuning techniques like LoRA will become critical.
Other methods in the documentation: https://github.com/huggingface/peft
Discover more from reviewer4you.com
Subscribe to get the latest posts to your email.





