The Power and Challenges of Unstructured Data in Relation to Retrieval-Augmented Generation
Unstructured data, encompassing formats such as text, images, audio, and video, makes up a majority of the data available in the digital age, often lacking a predefined data model or not easily fitting into relational tables.
As businesses and entities attempt to extract valuable insights from copious amounts of unstructured information, technologies like Retrieval-Augmented Generation (RAG) have gained prominence. This article elucidates the intersection of unstructured data with RAG technology, delineating its capabilities and challenges in contemporary data-driven scenarios.
Understanding Unstructured Data
Unstructured data refers to any data that does not have a recognizable structure or is not organized in a pre-defined manner. This can include:
- Text: Emails, books, articles, and social media posts.
- Images: Photographs, satellite images, and medical scans.
- Audio: Voice recordings, music files, and spoken content.
- Video: Movies, surveillance footage, and personal videos.
These data forms are primarily generated from varied sources like social media platforms, business transactions, multimedia content, and communication channels across various industries such as healthcare, finance, media, and entertainment. The richness of this data provides a fertile ground for deriving insights yet presents significant challenges in terms of processing and analysis due to its size and complexity.
The Significance of RAG in Handling Unstructured Data
RAG, or Retrieval-Augmented Generation, is a hybrid model combining the benefits of retrieval-based and generative AI systems. The model enhances response accuracy and relevance by retrieving information from a vast database of knowledge before generating content. This two-step approach allows the system to contextualize responses better, making it exceptionally beneficial for handling the nuances of unstructured data.
Technological Framework of RAG
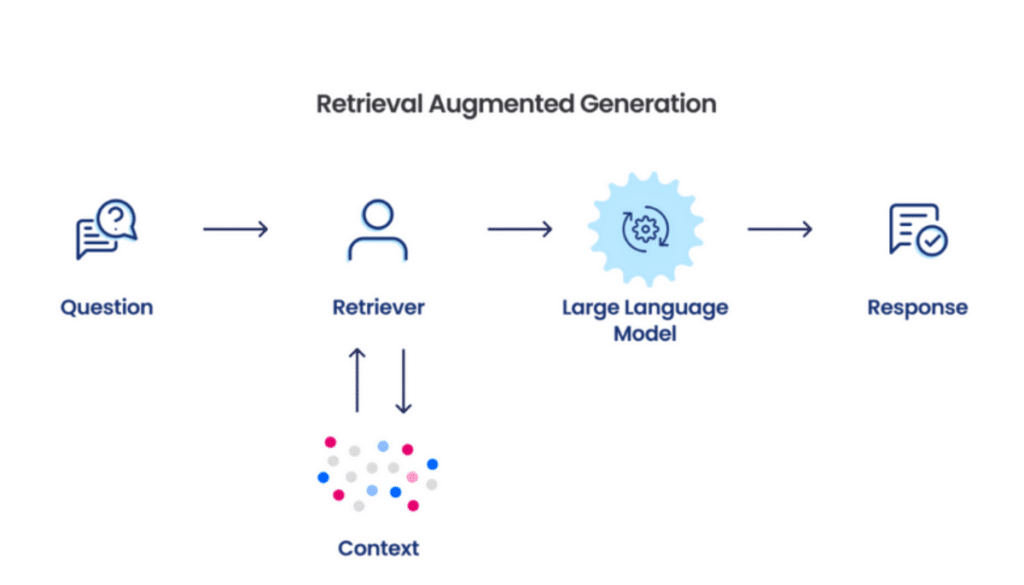
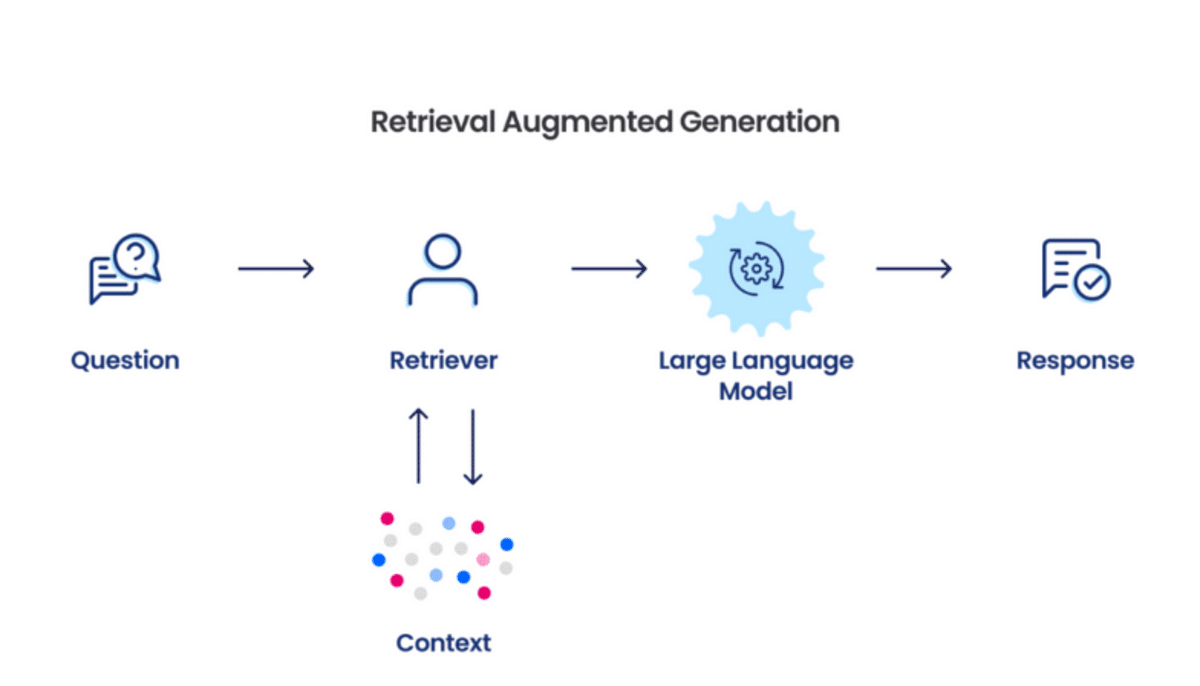
The operational framework of a RAG system involves several sophisticated components working synchronously:
- Prompt Submission: A user query is received as an input prompt to the RAG system.
- Data Retrieval: The system queries a vector database, retrieving relevant documents or data snippets based on semantic similarity to the input.
- Processing by LLM: The retrieved content, along with the original prompt, is fed into a large language model (LLM) like GPT (Generative Pre-trained Transformer). The LLM synthesizes the information to formulate a coherent and contextually appropriate response.
- Response Delivery: The response generated by the LLM is returned to the user, completing the interaction cycle.
For a detailed guide on constructing such a RAG pipeline, refer to this post: How to Build a RAG Pipeline.
Power of RAG in Utilizing Unstructured Data
The integration of RAG systems effectively addresses many challenges associated with unstructured data. By leveraging state-of-the-art machine learning models for both retrieval and generation, RAG can significantly enhance the precision of data processing. The accuracy of content retrieval is particularly critical as it ensures the relevance of the generated outputs, thereby reducing the noise and improving the quality of information presented to users.
Challenges in Managing Unstructured Data with RAG
Despite its advantages, the deployment of RAG systems entails several challenges:
- Scalability: Handling vast amounts of data requires immense computational resources and sophisticated scaling strategies.
- API Overload: Frequent and complex queries can overwhelm the system, leading to delays or failures in data retrieval.
- Data Relevance: Ensuring that the retrieved information remains relevant and up-to-date is an ongoing challenge, particularly with continuously evolving data sets.
Ethical and Security Considerations
The handling of sensitive and private information within unstructured data pools requires diligent ethical considerations and robust security protocols to prevent data breaches and ensure user privacy.
Future Trends in RAG and Unstructured Data
The ongoing advancements in AI and machine learning are poised to further refine the capabilities of RAG systems. With the continuous increase in data production, adaptive and more sophisticated RAG models are expected to emerge, catering to various sectors and applications.
Discover more from reviewer4you.com
Subscribe to get the latest posts to your email.





