This is a guest post from Andrew Ferlitsch, author of Deep Learning Patterns and Practices. It provides an introduction to deep neural networks in Python. Andrew is an expert on computer vision, deep learning, and operationalizing ML in production at Google Cloud AI Developer Relations.

This article examines the parts that make up neural networks and deep neural networks, as well as the fundamental different types of models (e.g. regression), their constituent parts (and how they contribute to model accuracy), and which tasks they are designed to learn. This article is meant for machine learning engineers who are familiar with Python and deep learning and want to get a thorough intro to the parts and functions of deep neural networks and related models.
Introduction to Neural Networks in Python
We will start this article with some basics on neural networks. First, we will cover the input layer to a neural network, then how this is connected to an output layer, and then how hidden layers are added in-between to become what is called a deep neural network. From there, we cover how the layers are made of nodes, how these nodes learn, and how layers are connected to each other to form fully connected neural networks.
We will also cover the fundamental different types of models. That is, there are different model types, such as regression and classification, which learn different types of tasks. Depending on the task you want to learn, determines the model type you will design a model for.
We will also cover the fundamentals of weights, biases, activations and optimizers, and how they contribute to the accuracy of the model.
Neural Network Basics
We will start with some basics on neural networks. First, we will cover the input layer to a neural network, then how this is connected to an output layer, and then how hidden layers are added in-between to become what is called a deep neural network. From there, we cover how the layers are made of nodes, what nodes do, and how layers are connected to each other to form fully connected neural networks.
Input Layer
The input layer to a neural network takes numbers! All the input data is converted to numbers. Everything is a number. The text becomes numbers, speech becomes numbers, pictures become numbers, and things that are already numbers are just numbers.
Neural networks take numbers either as vectors, matrices, or tensors. These are simply names for the number of dimensions in an array. A vector is a one-dimensional array, such as a list of numbers. A matrix is a two- dimensional array, like the pixels in a black and white image. And a tensor is any array of three or more dimensions. For example, a three dimensional array is a stack of matrices where each matrix is the same dimension. That’s it.

Fig. 1 Comparison of array shapes and corresponding names in deep learning.
Speaking of numbers, you might have heard terms like normalization or standardization. In standardization the numbers are converted to be centered around a mean of zero, with one standard deviation on each side of the mean. If you’re saying, ‘I don’t do statistics’ right about now, I know how you feel. But don’t worry. Packages like scikit-learn and numpy have library calls that do this for you. Standardization is basically a button to push, and it doesn’t even need a lever, so there are no parameters to set.
Speaking of packages, you’re going to be using a lot of numpy. What is numpy and why is it so popular? Given the interpretive nature of Python, the language handles large arrays poorly. Like really big, super big arrays of numbers – thousands, tens of thousands, millions of numbers. Think of Carl Sagan’s infamous quote on the size of the Universe – “billions and billions of stars.” That’s a tensor!
One day a C programmer got the idea to write, in low-level C, a high performance implementation for handling super big arrays, and then added an external Python wrapper. Numpy was born. Today numpy is a class with lots of useful methods and properties, like the property shape which tells you the shape (or dimensions) of the array, and the where() method which allows you to do SQL-like queries on your super big array.
All Python machine learning frameworks, including TensorFlow and PyTorch, will take as input on the input layer a numpy multidimensional array. And speaking of C, or Java, or C+, …, the input layer in a neural network is just like the parameters passed to a function in a programming language. That’s it.
Let’s get started by installing Python packages you will need. I assume you have Python installed (version 3.X). Whether you directly installed it, or it got installed as part of a larger package, like Anaconda, you got with it a nifty command-like tool called pip. This tool is used to install any Python package you will ever need again, from a single command invocation. You use pip install and then the name of the package. It goes to the global repository PyPi of Python packages and downloads and installs the package for you. It’s quite easy.
We want to start off by downloading and installing the Tensorflow framework, and the numpy package. Guess what their names are in the registry, tensorflow and numpy – thankfully very obvious. Let’s do it together. Go to the command line and issue the following:
cmd> pip install tensorflow
cmd> pip install numpyWith Tensorflow 2.0, Keras is built-in and the recommended model API, referred to now as TF.Keras.
TF.Keras is based on object oriented programming with a collection of classes and associated methods and properties. Let’s start simply. Say we have a dataset of housing data. Each row has fourteen columns of data. One column has the sale price of a home. We are going to call that the “label”. The other thirteen columns have information about the house, such as the square footage and property tax. It’s all numbers. We are going to call those the “features”. What we want to do is “learn” to predict (or estimate) the “label” from the “features”. Now before we had all this compute power and these awesome machine learning frameworks, data analysts did this stuff by hand or by using formulas in an Excel spreadsheet with some amount of data and lots and lots of linear algebra.We, however, will use Keras and TensorFlow.
We will start by first importing the Keras module from TensorFlow, and then instantiate an Input class object. For this class object, we define the shape or dimensions of the input. In our example, the input is a one-dimensional array (a vector) of 13 elements, one for each feature.
from tensorflow.keras import Input
Input(shape=(13,))When you run the above two lines in a notebook, you will see the output:
<tf.Tensor 'input_1:0' shape=(?, 13) dtype=float32>
This is showing you what Input(shape=(13,)) evaluates to. It produces a tensor object by the name ‘input_1:0’. This name will be useful later in assisting you in debugging your models. The ‘?’ in shape shows that the input object takes an unbounded number of entries (your examples or rows) of 13 elements each. That is, at run-time it will bind the number of one-dimensional vectors of 13 elements to the actual number of examples (rows) you pass in, referred to as the (mini) batch size. The ‘dtype’ shows the default data type of the elements, which in this case is a 32-bit float (single precision).
Take 40% off Deep Learning Patterns and Practices by entering fccferlitsch into the discount code box at checkout at manning.com.
Deep Neural Networks (DNN)
DeepMind, Deep Learning, Deep, Deep, Deep. Oh my, what’s all this? Deep in this context just means that the neural network has one or more layers between the input layer and the output layer. Visualize a directed graph in layers of depth. The root nodes are the input layer and the terminal nodes are the output layer. The layers in between are known as the hidden or deep layers. So a four-layer DNN architecture would look like this:
input layer hidden layer hidden layer output layer
To get started, we’ll assume every neural network node in every layer, except the output layer, is the same type of neural network node. And that every node on each layer is connected to every other node on the next layer. This is known as a fully connected neural network (FCNN), as depicted in figure 2. For example, if the input layer has three nodes and the next (hidden) layer has four nodes, then each node on the first layer is connected to all four nodes on the next layer for a total of 12 (3×4) connections.

Fig. 2 Deep neural networks have one or more hidden layers between the input and output layers. This is a fully-connected network, so the nodes at each level are all connected to each other.
Feed Forward networks
The DNN and Convolutional Neural Network (CNN), are known as feed forward neural networks. Feed forward means that data moves through the network sequentially, in one direction, from input to output layer). This is analogous to a function in procedural programming. The inputs are passed as parameters in the input layer, the function performs a sequenced set of actions based on the inputs (in the hidden layers) and outputs a result (the output layer).
When coding a forward feed network in TF.Keras, you will see two distinctive styles in blogs and other tutorials. I will briefly touch on both so when you see a code snippet in one style you can translate it to the other.
Sequential API Method
The Sequential API method is easier to read and follow for beginners, but the trade-off is that it is less flexible. Essentially, you create an empty forward feed neural network with the Sequential class object, and then “add” one layer at a time, until the output layer. In the examples below, the ellipses represent pseudo code.
from tensorflow.keras import Sequential
model = Sequential()
model.add( ...the first layer... )
model.add( ...the next layer... )
model.add( ...the output layer... )
A Create an empty model.
B Placeholders for adding layers in sequential order.
Alternatively, the layers can be specified in sequential order as a list passed as a parameter when instantiating the Sequential class object.
model = Sequential([ ...the first layer...,
...the next layer...,
...the output layer...
])So, you might ask, when would one use the add() method versus specifying as a list in the instantiation of the Sequential object. Well, both methods generate the same model and behavior, so it’s a matter of personal preference. For myself, I tend to use the more verbose add() method in instructional and demonstration material for clarity. But, if I am writing code for production, I will use the sparser list method, where I can visualize and edit the code more easily.
Functional API Method
The Functional API method is more advanced, allowing you to construct models that are non-sequential in flow –such as branches, skip links, and multiple inputs and outputs. You build the layers separately and then “tie” them together. This latter step gives you the freedom to connect layers in creative ways. Essentially, for a forward feed neural network, you create the layers, bind them to another layer(s), and then pull all the layers together in a final instantiation of a Model class object.
input = layers.(...the first layer...)
hidden = layers.(...the next layer...)( ...the layer to bind to... )
output = layers.(...the output layer...)( /the layer to bind to... )
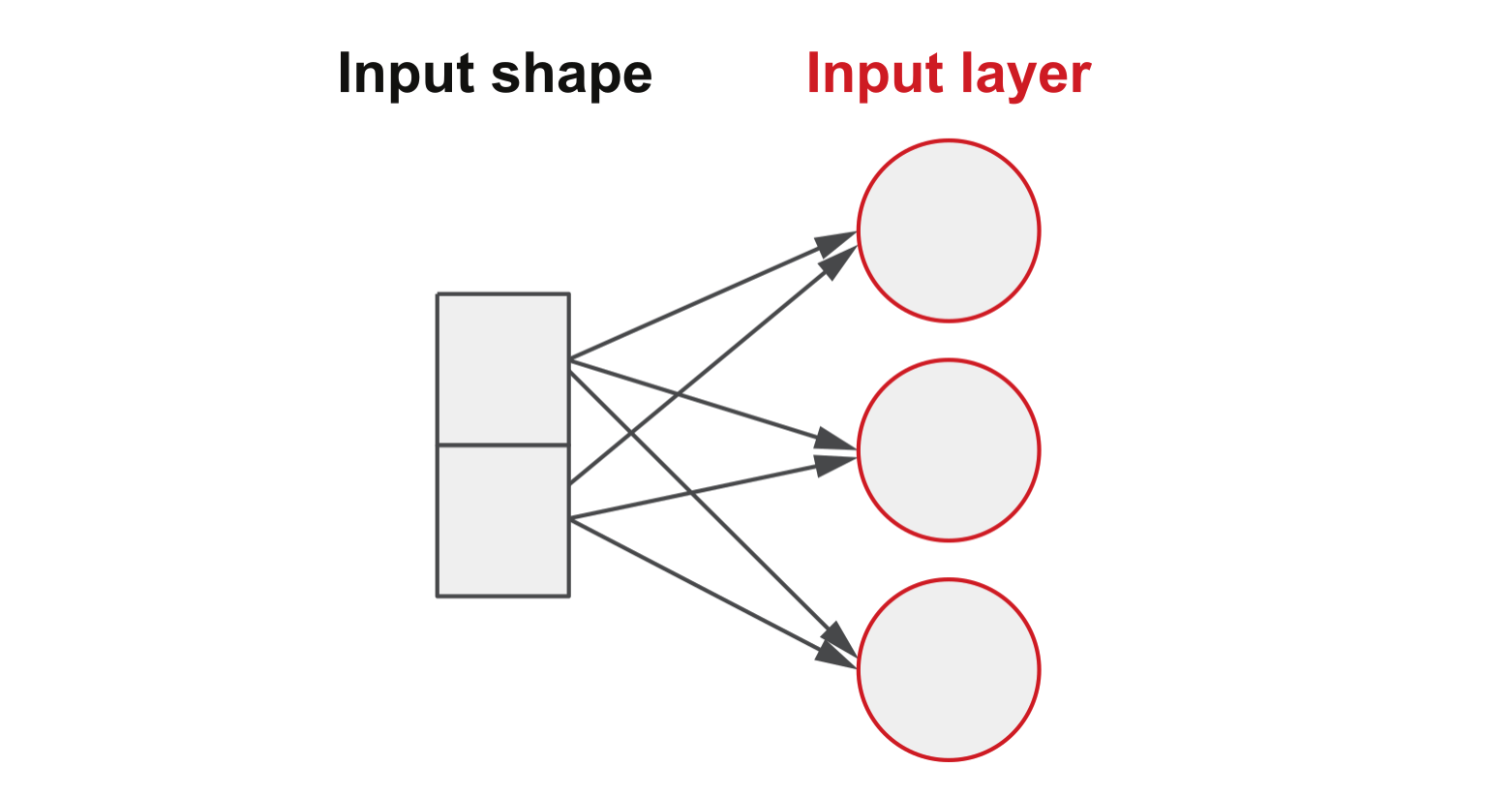
model = Model(input, output)Input Shape vs Input Layer
The input shape and input layer can be confusing at first. They are not the same thing. More specifically, the number of nodes in the input layer does not need to match the shape of the input vector. That’s because every element in the input vector will be passed to every node in the input layer, as depicted in figure 2a.

Fig. 2a Shows the difference between the input (shape) and input layer and how every element in the input is connected to every node in the input layer.
For example, if our input layer is ten nodes, and we use our earlier example of a thirteen-element input vector, we will have 130 connections (10 x 13) between the input vector and the input layer.
Each one of these connections between an element in the input vector and a node in the input layer will have a weight and each node in the input layer has a bias. Think of each connection between the input vector and input layer, as well as connections between layers, as sending a signal forward in how strongly it believes the input value will contribute to what the model predictions. We need to have a measurement of the strength of this signal, and that is what the weight does. It is a coefficient that is multiplied against the input value for the input layer, and previous value for subsequent layers. Now each one of these connections is like a vector on an x-y plane. Ideally, we would want each of these vectors to cross the y-axis at the same central point, e.g., 0 origin. But they don’t. To make the vectors relative to each other, the bias is the offset of each vector from the central point on the y-axis.
The weights and biases are what the neural network will “learn” during training. The weights and biases are also referred to as parameters. That is, these values stay with the model after it is trained. This operation will otherwise be invisible to you.
Dense Layer
In TF.Keras, layers in a fully connected neural network (FCNN) are called Dense layers. A Dense layer is defined as having an “n” number of nodes, and is fully connected to the previous layer. Let’s continue and define in TF.Keras a three layer neural network, using the Sequential API method, for our example. Our input layer will be ten nodes, and take as input a thirteen element vector (i.e., the thirteen features), which will be connected to a second (hidden) layer of ten nodes, which will then be connected to a third (output) layer of one node. Our output layer only needs to be one node, since it will be outputting a single real value (e.g. – the predicted price of the house). This is an example where we are going to use a neural network as a regressor. That means, the neural network will output a single real number.
input layer = 10 nodes hidden layer = 10 nodes output layer = 1 node
For input and hidden layers, we can pick any number of nodes. The more nodes we have, the better the neural network can learn, but more nodes means more complexity and more time in training and predicting.
In the following code example, we have three add() calls to the class object Dense(). The add() method “adds” the layers in the same sequential order we specified them in. The first (positional) parameter is the number of nodes, ten in the first and second layer and one in the third layer. Notice how in the first Dense() layer we added the (keyword) parameter input_shape. This is where we will define the input vector and connect it to the first (input) layer in a single instantiation of Dense().
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
# Add the first (input) layer (10 nodes) with input shape 13 element vector (1D).
model.add(Dense(10, input_shape=(13,)))
# Add the second (hidden) layer of 10 nodes.
model.add(Dense(10))
# Add the third (output) layer of 1 node.
model.add(Dense(1))Alternatively, we can define the sequential sequence of the layers as a list parameter when instantiating the Sequential class object.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
# Add the first (input) layer (10 nodes)
Dense(10, input_shape=(13,)),
# Add the second (hidden) layer of 10 nodes.
Dense(10),
# Add the third (output) layer of 1 node.
Dense(1)
])
Let’s now do the same but use the Functional API method. We start by creating an input vector by instantiating an Input class object. The (positional) parameter to the Input() object is the shape of the input, which can be a vector, matrix or tensor. In our example, we have a vector that is thirteen elements long. So our shape is (13,). I am sure you noticed the trailing comma. That’s to overcome a quirk in Python. Without the comma, a (13) is evaluated as an expression. That is, the integer value 13 is surrounded by a parenthesis. Adding a comma will tell the interpreter this is a tuple (an ordered set of values).
Next, we create the input layer by instantiating a Dense class object. The positional parameter to the Dense() object is the number of nodes; which in our example is ten. Note the peculiar syntax that follows with a (inputs). The Dense() object is a callable. That is, the object returned by instantiating the Dense() object can be callable as a function. So we call it as a function, and in this case, the function takes as a (positional) parameter the input vector (or layer output) to connect it to; hence we pass it inputs so the input vector is bound to the ten node input layer.
Next, we create the hidden layer by instantiating another Dense() object with ten nodes, and using it as a callable, we (fully) connect it to the input layer.
Then we create the output layer by instantiating another Dense() object with one node, and using it as a callable, we (fully) connect it to the hidden layer.
Finally, we put it altogether by instantiating a Model class object, passing it the (positional) parameters for the input vector and output layer. Remember, all the other layers in-between are already connected so we don’t need to specify them when instantiating the Model() object.
from tensorflow.keras import Input, Model
from tensorflow.keras.layers import Dense
inputs = Input((13,))
input = Dense(10)(inputs)
hidden = Dense(10)(input)
output = Dense(1)(hidden)
model = Model(inputs, output)
Activation Functions
When training or predicting (inference), each node in a layer will output a value to the nodes in the next layer. We don’t always want to pass the value ‘as-is’, but instead sometimes we want to change the value in some manner. This process is called an activation function. Think of a function that returns some result, like return result. In the case of an activation function, instead of returning result, we would return the result of passing the result value to another (activation) function, like return A(result), where A() is the activation function. Conceptually, you can think of this as:
def layer(params):
""" inside are the nodes """
result = some_calculations
return A(result)
def A(result):
""" modifies the result """
return some_modified_value_of_result
Activation functions assist neural networks in learning faster and better. By default, when no activation function is specified, the values from one layer are passed as-is (unchanged) to the next layer. The most basic activation function is a step function. If the value is greater than 0, then a 1 is outputted; otherwise a zero. The step function hasn’t been used in a long, long time.
Let’s pause for a moment and discuss the purpose of an activation function. You likely have heard the phrase non-linearity. What is this? To me, more importantly, is what it is not?
In traditional statistics, we worked in low dimensional space where there was a strong linear correlation between the input space and output space. This correlation could be computed as a polynomial transformation of the input that, when transformed, had a linear correlation to the output. The most fundamental example is the slope of a line, which is represented as y = mx + b. In this case, x and y are coordinates of the line, and we want to fit the value of m, the slope, and b, where the line intercepts the y access.
In deep learning, we work in high dimensional space where there is substantial non-linearity between the input space and output space. What is non-linearity? It means that an input is not (near) uniformly related to an output based on a polynomial transformation of the input. For example, let’s say one’s property tax is a fixed percentage rate (r) of the house value. In this case, the property tax can be represented by a function that multiplies the rate by the house value — thus having a linear (i.e., straight line) relationship between value (input) and property tax (output).
tax = F(value) = r * value
Let’s look at the logarithmic scale for measuring earthquakes, where an increase of one, means the power released is ten times greater. For example, an earthquake of 4 is 10 times stronger than a 3. By applying a logarithmic transform to the input power we have a linear relationship between power and scale.
scale = F(power) = log(power)
In a non-linear relationship, sequences within the input have different linear relationships to the output, and in deep learning we want to learn both the separation points as well as the linear functions for each input sequence. For example, consider age vs. income to demonstrate a non-linear relationship. In general, toddlers have no income, grade-school children have an allowance, early-teens earn an allowance + money for chores, later teens earn money from jobs, and then when they go to college their income drops to zero! After college, their income gradually increases until retirement, when it becomes fixed. We could model this nonlinearity as sequences across age and learn a linear function for each sequence, such as depicted below.
income = F1(age) = 0 for age [0..5] income = F2(age) = c1 for age[6..9] income = F3(age) = c1 + (w1 * age) for age[10..15] income = F4(age) = (w2 * age) for age[16..18] income = F5(age) = 0 for age[19..22] income = F6(age) = (w3 * age) for age[23..64] income = F7(age) = c2 for age [65+]
Activation functions assist in finding the non-linear separations and corresponding clustering of nodes within input sequences which then learn the (near) linear relationship to the output.
There are three activation functions you will use most of the time: the rectified linear unit (ReLU); sigmoid; softmax. We will start with the ReLU, since it is the one that is most used in all but the output layer of a model. The sigmoid and softmax activation we will then cover when we look at how different model types affect the design of the output layer.
The rectified linear unit, as depicted in figure 3, passes values greater than zero as-is (unchanged); otherwise zero (no signal).

The rectified linear unit is generally used between layers. While early researchers used different activation functions, such as a hyperbolic tangent, between layers, researchers found that the ReLU produced the best result in training a model. In our example, we will add a rectified linear unit between each layer.
model = Sequential()
# Add the first (input) layer (10 nodes) with input shape 13 element vector (1D).
model.add(Dense(10, input_shape=(13,)))
# Pass the output from the input layer through a rectified linear unit activation # function.
model.add(ReLU())
# Add the second (hidden) layer (10 nodes).
model.add(Dense(10))
# Pass the output from the input layer through a rectified linear unit activation # function.
model.add(ReLU())
# Add the third (output) layer of 1 node.
model.add(Dense(1))Let’s take a look inside our model object and see if we constructed what we think we did. You can do this using the summary() method. It will show in sequential order a summary of each layer.
model.summary()Layer (type) Output Shape Param # ================================================================= dense_56 (Dense) (None, 10) 140 _________________________________________________________________ re_lu_18 (ReLU) (None, 10) 0 _________________________________________________________________ dense_57 (Dense) (None, 10) 110 _________________________________________________________________ re_lu_19 (ReLU) (None, 10) 0 _________________________________________________________________ dense_58 (Dense) (None, 1) 11 ================================================================= Total params: 261 Trainable params: 261 Non-trainable params: 0 _________________________________________________________________
For this code example, you see the summary starts with a Dense layer of ten nodes (input layer), followed by a ReLU activation function, followed by a second Dense layer (hidden) of ten nodes, followed by a ReLU activation function, and finally followed by a Dense layer (output) of one node. So, yes, we got what we expected.
Next, let’s look at the parameter field in the summary. See how, for the input layer, it shows 140 parameters. How is that calculated? We have 13 inputs and 10 nodes, so 13 x 10 is 130. Where does 140 come from? Each connection between the inputs and each node has a weight, which adds up to 130. But each node has an additional bias. That’s ten nodes, so 130 + 10 = 140. As I’ve said, it’s the weights and biases that the neural network will “learn” during training. A bias is a learned offset, conceptually equivalent to the y-intercept (b) in the slope of a line, which is where the line intercepts the y-axis:
y = b + mx
At the next (hidden) layer you see 110 params. That’s ten outputs from the input layer connected to each of the ten nodes from the hidden layer (10×10) plus the ten biases for the nodes in the hidden layers, for a total of 110 parameters to “learn”.
Shorthand Syntax
TF.Keras provides a shorthand syntax when specifying layers. You don’t actually need to separately specify activation functions between layers, as we did above. Instead, you can specify the activation function as a (keyword) parameter when instantiating a Dense() layer.
You might ask, why not then simply always use the shorthand syntax? As you will see later in the book, where in today’s model architecture the activation function is preceded by another intermediate layer — batch normalization, or precedes the layer altogether — pre-activation batch normalization.
The code example below does exactly the same as the code above.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
# Add the first (input) layer (10 nodes) with input shape 13 element vector (1D).
model.add(Dense(10, input_shape=(13,), activation='relu'))
# Add the second (hidden) layer (10 nodes).
model.add(Dense(10, activation='relu'))
# Add the third (output) layer of 1 node.
model.add(Dense(1))#A The activation function is specified as a keyword parameter in the layer.Let’s call the summary() method on this model.
model.summary()Layer (type) Output Shape Param # ================================================================= dense_56 (Dense) (None, 10) 140 _________________________________________________________________ re_lu_18 (ReLU) (None, 10) 0 _________________________________________________________________ dense_57 (Dense) (None, 10) 110 _________________________________________________________________ re_lu_19 (ReLU) (None, 10) 0 _________________________________________________________________ dense_58 (Dense) (None, 1) 11 ================================================================= Total params: 261 Trainable params: 261 Non-trainable params: 0
Hum, you don’t see the activations between the layers as you did in the earlier example. Why not? It’s a quirk in how the summary() method displays output. They are still there.
Improving accuracy with optimizer
Once you’ve completed building the forward feed portion of your neural network, as we have for our simple example, we now need to add a few things for training the model. This is done with the compile() method. This step adds the backward propagation during training. Let’s define and explore this concept.
Each time we send data (or a batch of data) forward through the neural network, the neural network calculates the errors in the predicted results (known as the loss) from the actual values (called labels) and uses that information to incrementally adjust the weights and biases of the nodes. This, for a model, is the process of learning.
The calculation of the error, as I’ve said, is called a loss. It can be calculated in many different ways. Since we designed our example neural network to be a regresser (meaning that the output, house price, is a real value), we want to use a loss function that is best suited for a regresser. Generally, for this type of neural network, we use the Mean Square Error method of calculating a loss. In Keras, the compile() method takes a (keyword) parameter loss where we can specify how we want to calculate the loss. We are going to pass it the value ‘mse’ for Mean Square Error.
The next step in the process is the optimizer that occurs during backward propagation. The optimizer is based on gradient descent; where different variations of the gradient descent algorithm can be selected. These terms can be hard to understand at first. Essentially, each time we pass data through the neural network we use the calculated loss to decide how much to change the weights and biases in the layers by. The goal is to gradually get closer and closer to the correct values for the weights and biases to accurately predict or estimate the “label” for each example. This process of progressively getting closer and closer to the accurate values is called convergence. The job of the optimizer is to calculate the updates to the weights to progressively get closer to the accurate values to reach convergence.
As the loss gradually decreases we are converging and once the loss plateaus out, we have convergence, and the result is the accuracy of the neural network. Before using gradient descent, the methods used by early AI researchers could take years on a supercomputer to find convergence on a non-trivial problem. After the discovery of using the gradient descent algorithm, this time reduced to days, hours and even just minutes on ordinary compute power. Let’s skip the math and just say that gradient descent is the data scientist’s pixie dust that makes convergence possible.
For our regressor neural network, we will use the rmsprop method (root mean square property).
model.compile(loss="mse", optimizer="rmsprop")Now we have completed building your first ‘trainable’ neural network.
That’s all for now. If you want to learn more about the book, check it out on Manning’s liveBook platform here.
Related
Discover more from reviewer4you.com
Subscribe to get the latest posts to your email.



